DQL(Data Query Language): 查询数据
⽤来查询数据库表中的记录/数据。 相关关键字包括:SELECT、WHERE等。
基本查询
要查询数据库表的数据,我们使用如下的SQL语句:
SELECT * FROM <表名>假设表名是students,要查询students表的所有行,我们用如下SQL语句:
SELECT * FROM students;使用SELECT * FROM students时,SELECT是关键字,表示将要执行一个查询,*表示“所有列”,FROM表示将要从哪个表查询,本例中是students表。
注意❗
该SQL将查询出
students表的所有数据。注意:查询结果也是一个二维表,它包含列名和每一行的数据。
SELECT语句其实并不要求一定要有FROM子句。我们来试试下面的SELECT语句:
SELECT 100+200;上述查询会直接计算出表达式的结果。虽然SELECT可以用作计算,但它并不是SQL的强项。但是,不带FROM子句的SELECT语句有一个有用的用途,就是用来判断当前到数据库的连接是否有效。许多检测工具会执行一条SELECT 1;来测试数据库连接。
WHERE: 条件查询
使用SELECT * FROM <表名>可以查询到一张表的所有记录。但是,很多时候,我们并不希望获得所有记录,而是根据条件选择性地获取指定条件的记录,例如,查询分数在80分以上的学生记录。在一张表有数百万记录的情况下,获取所有记录不仅费时,还费内存和网络带宽。
SELECT语句可以通过WHERE条件来设定查询条件,查询结果是满足查询条件的记录。例如,要指定条件“分数在80分或以上的学生”,写成WHERE条件就是SELECT * FROM students WHERE score >= 80。
其中,WHERE关键字后面的score >= 80就是条件。score是列名,该列存储了学生的成绩,因此,score >= 80就筛选出了指定条件的记录:
SELECT * FROM students WHERE score >= 80;条件查询的语法就是:
SELECT * FROM <表名> WHERE <条件表达式>AND
条件表达式可以用<条件1> AND <条件2>表达满足条件1并且满足条件2。例如,符合条件“分数在80分或以上”,并且还符合条件“男生”,把这两个条件写出来:
- 条件1:根据score列的数据判断:
score >= 80; - 条件2:根据gender列的数据判断:
gender = 'M',注意gender列存储的是字符串,需要用单引号括起来。
就可以写出WHERE条件:score >= 80 AND gender = 'M':
SELECT * FROM students WHERE score >= 80 AND gender = 'M';OR
第二种条件是<条件1> OR <条件2>,表示满足条件1或者满足条件2。例如,把上述AND查询的两个条件改为OR,查询结果就是“分数在80分或以上”或者“男生”,满足任意之一的条件即选出该记录:
SELECT * FROM students WHERE score >= 80 OR gender = 'M';很显然OR条件要比AND条件宽松,返回的符合条件的记录也更多。
NOT
第三种条件是NOT <条件>,表示“不符合该条件”的记录。例如,写一个“不是2班的学生”这个条件,可以先写出“是2班的学生”:class_id = 2,再加上NOT:NOT class_id = 2:
SELECT * FROM students WHERE NOT class_id = 2;上述NOT条件NOT class_id = 2其实等价于class_id <> 2,因此,NOT查询不是很常用。
要组合三个或者更多的条件,就需要用小括号()表示如何进行条件运算。例如,编写一个复杂的条件:分数在80以下或者90以上,并且是男生:
SELECT * FROM students WHERE (score < 80 OR score > 90) AND gender = 'M';注意❗
如果不加括号,条件运算按照
NOT、AND、OR的优先级进行,即NOT优先级最高,其次是AND,最后是OR。加上括号可以改变优先级。
常用的条件表达式
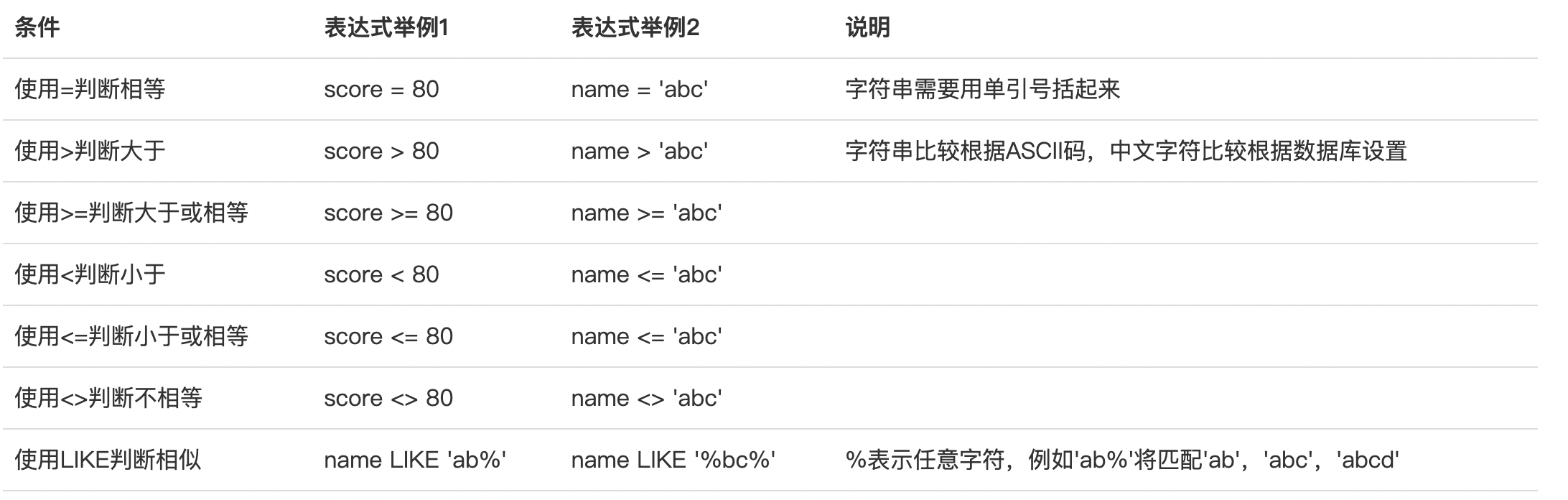
BETWEEN
查询分数在60分(含)~90分(含)之间的学生可以使用的WHERE语句是:
WHERE score >= 60 AND score <= 90与下面的语句是等价的。
WHERE score BETWEEN 60 AND 90IN
也可以使用 IN 关键值指定范围值,在成绩为60和90的范围内进行查找。
WHERE score IN (60, 90)LIKE: 模糊查询
比如用下面的语句来查询姓王的用户。
WHERE name IIKE '王%'其中% 表示任意多个字符,也可以使用_下划线来匹配一个字符:
WHERE name IIKE '王_'REGEXP
如果复杂的规则也可以使用正则表达式进行匹配:
WHERE name REGEXP '[0-9]'IS
比如下面查找没有填写邮箱的用户。
WHERE email IS null等价于下面的添加< >的写法:
WHERE email <=> null也可以查询填写了邮箱的用户。
WHERE email IS NOT null投影查询
使用SELECT * FROM <表名> WHERE <条件>可以选出表中的若干条记录。我们注意到返回的二维表结构和原表是相同的,即结果集的所有列与原表的所有列都一一对应。
如果我们只希望返回某些列的数据,而不是所有列的数据,我们可以用SELECT 列1, 列2, 列3 FROM ...,让结果集仅包含指定列。这种操作称为投影查询。
例如,从students表中返回id、score和name这三列:
SELECT id, score, name FROM students;这样返回的结果集就只包含了我们指定的列,并且,结果集的列的顺序和原表可以不一样。
使用SELECT 列1, 列2, 列3 FROM ...时,还可以给每一列起个别名,这样,结果集的列名就可以与原表的列名不同。它的语法是SELECT 列1 别名1, 列2 别名2, 列3 别名3 FROM ...。
例如,以下SELECT语句将列名score重命名为points,而id和name列名保持不变:
SELECT id, score points, name FROM students;投影查询同样可以接WHERE条件,实现复杂的查询:
SELECT id, score points, name FROM students WHERE gender = 'M';ORDER BY:排序
我们使用SELECT查询时,细心的读者可能注意到,查询结果集通常是按照id排序的,也就是根据主键排序。这也是大部分数据库的做法。如果我们要根据其他条件排序怎么办?可以加上ORDER BY子句。例如按照成绩从低到高进行排序:
SELECT id, name, gender, score FROM students ORDER BY score;如果要反过来,按照成绩从高到底排序,我们可以加上DESC表示“倒序”:
SELECT id, name, gender, score FROM students ORDER BY score DESC;如果score列有相同的数据,要进一步排序,可以继续添加列名。例如,使用ORDER BY score DESC, gender表示先按score列倒序,如果有相同分数的,再按gender列排序:
SELECT id, name, gender, score FROM students ORDER BY score DESC, gender;默认的排序规则是ASC:“升序”,即从小到大。ASC可以省略,即ORDER BY score ASC和ORDER BY score效果一样。
如果有WHERE子句,那么ORDER BY子句要放到WHERE子句后面。例如,查询一班的学生成绩,并按照倒序排序:
SELECT id, name, gender, score
FROM students
WHERE class_id = 1
ORDER BY score DESC;LIMIT:分页查询
使用SELECT查询时,如果结果集数据量很大,比如几万行数据,放在一个页面显示的话数据量太大,不如分页显示,每次显示100条。
要实现分页功能,实际上就是从结果集中显示第1100条记录作为第1页,显示第101200条记录作为第2页,以此类推。
因此,分页实际上就是从结果集中“截取”出第M~N条记录。这个查询可以通过LIMIT <N-M> OFFSET <M>子句实现。我们先把所有学生按照成绩从高到低进行排序:
SELECT id, name, gender, score FROM students ORDER BY score DESC;现在,我们把结果集分页,每页3条记录。要获取第1页的记录,可以使用LIMIT 3 OFFSET 0:
SELECT id, name, gender, score
FROM students
ORDER BY score DESC
LIMIT 3 OFFSET 0;上述查询LIMIT 3 OFFSET 0表示,对结果集从0号记录开始,最多取3条。注意SQL记录集的索引从0开始。
如果要查询第2页,那么我们只需要“跳过”头3条记录,也就是对结果集从3号记录开始查询,把OFFSET设定为3:
SELECT id, name, gender, score
FROM students
ORDER BY score DESC
LIMIT 3 OFFSET 3;类似的,查询第3页的时候,OFFSET应该设定为6:
SELECT id, name, gender, score
FROM students
ORDER BY score DESC
LIMIT 3 OFFSET 6;查询第4页的时候,OFFSET应该设定为9:
SELECT id, name, gender, score
FROM students
ORDER BY score DESC
LIMIT 3 OFFSET 9;由于第4页只有1条记录,因此最终结果集按实际数量1显示。LIMIT 3表示的意思是“最多3条记录”。
可见,分页查询的关键在于,首先要确定每页需要显示的结果数量pageSize(这里是3),然后根据当前页的索引pageIndex(从1开始),确定LIMIT和OFFSET应该设定的值:
LIMIT总是设定为pageSize;OFFSET计算公式为pageSize * (pageIndex - 1)。
这样就能正确查询出第N页的记录集。
如果原本记录集一共就10条记录,但我们把OFFSET设置为20,会得到什么结果呢?
SELECT id, name, gender, score
FROM students
ORDER BY score DESC
LIMIT 3 OFFSET 20;OFFSET超过了查询的最大数量并不会报错,而是得到一个空的结果集。
注意❗
OFFSET是可选的,如果只写LIMIT 15,那么相当于LIMIT 15 OFFSET 0。在MySQL中,
LIMIT 15 OFFSET 30还可以简写成LIMIT 30, 15。使用
LIMIT <M> OFFSET <N>分页时,随着N越来越大,查询效率也会越来越低。
聚合查询
如果我们要统计一张表的数据量,例如,想查询students表一共有多少条记录,难道必须用SELECT * FROM students查出来然后再数一数有多少行吗?
这个方法当然可以,但是比较弱智。对于统计总数、平均数这类计算,SQL提供了专门的聚合函数,使用聚合函数进行查询,就是聚合查询,它可以快速获得结果。
COUNT()
仍然以查询students表一共有多少条记录为例,我们可以使用SQL内置的COUNT()函数查询:
SELECT COUNT(*) FROM students;COUNT(*)表示查询所有列的行数,要注意聚合的计算结果虽然是一个数字,但查询的结果仍然是一个二维表,只是这个二维表只有一行一列,并且列名是COUNT(*)。
通常,使用聚合查询时,我们应该给列名设置一个别名,便于处理结果:
SELECT COUNT(*) num FROM students;COUNT(*)和COUNT(id)实际上是一样的效果。另外注意,聚合查询同样可以使用WHERE条件,因此我们可以方便地统计出有多少男生、多少女生、多少80分以上的学生等:
SELECT COUNT(*) boys FROM students WHERE gender = 'M';其他聚合函数 MAX()和MIN() 等
除了COUNT()函数外,SQL还提供了如下聚合函数:
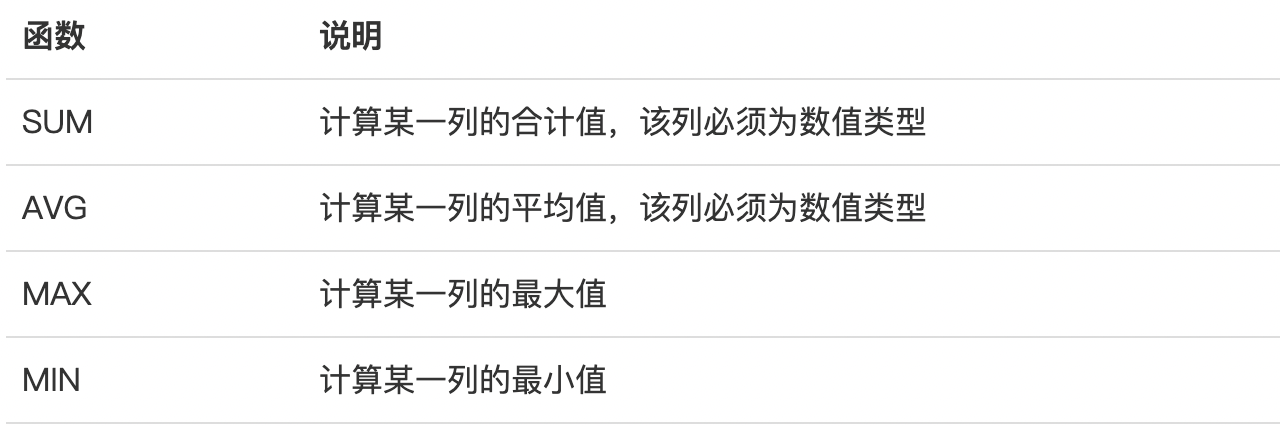
注意,MAX()和MIN()函数并不限于数值类型。如果是字符类型,MAX()和MIN()会返回排序最后和排序最前的字符。
要统计男生的平均成绩,我们用下面的聚合查询:
SELECT AVG(score) average FROM students WHERE gender = 'M';注意❗
要特别注意:如果聚合查询的
WHERE条件没有匹配到任何行,COUNT()会返回0,而SUM()、AVG()、MAX()和MIN()会返回NULL:
SELECT AVG(score) average FROM students WHERE gender = 'X';GROUP BY: 分组
如果我们要统计一班的学生数量,我们知道,可以用SELECT COUNT(*) num FROM students WHERE class_id = 1;。如果要继续统计二班、三班的学生数量,难道必须不断修改WHERE条件来执行SELECT语句吗?
对于聚合查询,SQL还提供了“分组聚合”的功能。我们观察下面的聚合查询:
SELECT COUNT(*) num FROM students GROUP BY class_id;执行这个查询,COUNT()的结果不再是一个,而是3个,这是因为,GROUP BY子句指定了按class_id分组,因此,执行该SELECT语句时,会把class_id相同的列先分组,再分别计算,因此,得到了3行结果。
但是这3行结果分别是哪三个班级的,不好看出来,所以我们可以把class_id列也放入结果集中:
SELECT class_id, COUNT(*) num FROM students GROUP BY class_id;这下结果集就可以一目了然地看出各个班级的学生人数。我们再试试把name放入结果集:
SELECT name, class_id, COUNT(*) num FROM students GROUP BY class_id;不出意外,执行这条查询我们会得到一个语法错误,因为在任意一个分组中,只有class_id都相同,name是不同的,SQL引擎不能把多个name的值放入一行记录中。因此,聚合查询的列中,只能放入分组的列。
注意❗
注意:AlaSQL并没有严格执行SQL标准,上述SQL在浏览器可以正常执行,但是在MySQL、Oracle等环境下将报错,请自行在MySQL中测试。
也可以使用多个列进行分组。例如,我们想统计各班的男生和女生人数:
SELECT class_id, gender, COUNT(*) num FROM students GROUP BY class_id, gender;上述查询结果集一共有6条记录,分别对应各班级的男生和女生人数。
多表查询
SELECT查询不但可以从一张表查询数据,还可以从多张表同时查询数据。查询多张表的语法是:SELECT * FROM <表1> <表2>。
例如,同时从students表和classes表的“乘积”,即查询数据,可以这么写:
SELECT * FROM students, classes;这种一次查询两个表的数据,查询的结果也是一个二维表,它是students表和classes表的“乘积”,即students表的每一行与classes表的每一行都两两拼在一起返回。结果集的列数是students表和classes表的列数之和,行数是students表和classes表的行数之积。
注意❗
这种多表查询又称笛卡尔查询,使用笛卡尔查询时要非常小心,由于结果集是目标表的行数乘积,对两个各自有100行记录的表进行笛卡尔查询将返回1万条记录,对两个各自有1万行记录的表进行笛卡尔查询将返回1亿条记录。
你可能还注意到了,上述查询的结果集有两列id和两列name,两列id是因为其中一列是students表的id,而另一列是classes表的id,但是在结果集中,不好区分。两列name同理
要解决这个问题,我们仍然可以利用投影查询的“设置列的别名”来给两个表各自的id和name列起别名:
SELECT
students.id sid,
students.name,
students.gender,
students.score,
classes.id cid,
classes.name cname
FROM students, classes;注意,多表查询时,要使用表名.列名这样的方式来引用列和设置别名,这样就避免了结果集的列名重复问题。但是,用表名.列名这种方式列举两个表的所有列实在是很麻烦,所以SQL还允许给表设置一个别名,让我们在投影查询中引用起来稍微简洁一点:
SELECT
s.id sid,
s.name,
s.gender,
s.score,
c.id cid,
c.name cname
FROM students s, classes c;注意❗
注意到
FROM子句给表设置别名的语法是FROM <表名1> <别名1>, <表名2> <别名2>。这样我们用别名s和c分别表示students表和classes表。
多表查询也是可以添加WHERE条件的,我们来试试:
SELECT
s.id sid,
s.name,
s.gender,
s.score,
c.id cid,
c.name cname
FROM students s, classes c
WHERE s.gender = 'M' AND c.id = 1;这个查询的结果集每行记录都满足条件s.gender = 'M'和c.id = 1。添加WHERE条件后结果集的数量大大减少了。
连接查询
连接查询是另一种类型的多表查询。连接查询对多个表进行JOIN运算,简单地说,就是先确定一个主表作为结果集,然后,把其他表的行有选择性地“连接”在主表结果集上。
例如,我们想要选出students表的所有学生信息,可以用一条简单的SELECT语句完成:
SELECT s.id, s.name, s.class_id, s.gender, s.score FROM students s;但是,假设我们希望结果集同时包含所在班级的名称,上面的结果集只有class_id列,缺少对应班级的name列。
现在问题来了,存放班级名称的name列存储在classes表中,只有根据students表的class_id,找到classes表对应的行,再取出name列,就可以获得班级名称。
INNER JOIN
这时,连接查询就派上了用场。我们先使用最常用的一种内连接——INNER JOIN来实现:
SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score
FROM students s
INNER JOIN classes c
ON s.class_id = c.id;注意INNER JOIN查询的写法是 SELECT ... FROM <表1> INNER JOIN <表2> ON <条件...> :
- 先确定主表,仍然使用
FROM <表1>的语法; - 再确定需要连接的表,使用
INNER JOIN <表2>的语法; - 然后确定连接条件,使用
ON <条件...>,这里的条件是s.class_id = c.id,表示students表的class_id列与classes表的id列相同的行需要连接; - 可选:加上
WHERE子句、ORDER BY等子句。
使用别名不是必须的,但可以更好地简化查询语句。
OUTER JOIN
那什么是内连接(INNER JOIN)呢?先别着急,有内连接(INNER JOIN)就有外连接(OUTER JOIN)。我们把内连接查询改成外连接查询,看看效果:
SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score
FROM students s
RIGHT OUTER JOIN classes c
ON s.class_id = c.id;执行上述RIGHT OUTER JOIN可以看到,和INNER JOIN相比,RIGHT OUTER JOIN多了一行,多出来的一行是“四班”,但是,学生相关的列如name、gender、score都为NULL。
这也容易理解,因为根据ON条件s.class_id = c.id,classes表的id=4的行正是“四班”,但是,students表中并不存在class_id=4的行。
有RIGHT OUTER JOIN,就有LEFT OUTER JOIN,以及FULL OUTER JOIN。它们的区别是:
INNER JOIN只返回同时存在于两张表的行数据,由于students表的class_id包含1,2,3,classes表的id包含1,2,3,4,所以,INNER JOIN根据条件s.class_id = c.id返回的结果集仅包含1,2,3。
RIGHT OUTER JOIN返回右表都存在的行。如果某一行仅在右表存在,那么结果集就会以NULL填充剩下的字段。
LEFT OUTER JOIN则返回左表都存在的行。如果我们给students表增加一行,并添加class_id=5,由于classes表并不存在id=5的行,所以,LEFT OUTER JOIN的结果会增加一行,对应的class_name是NULL:
SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score
FROM students s
LEFT OUTER JOIN classes c
ON s.class_id = c.id;最后,我们使用FULL OUTER JOIN,它会把两张表的所有记录全部选择出来,并且,自动把对方不存在的列填充为NULL:
SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score
FROM students s
FULL OUTER JOIN classes c
ON s.class_id = c.id;多种JOIN查询的区别
对于这么多种JOIN查询,到底什么使用应该用哪种呢?其实我们用图来表示结果集就一目了然了。
假设查询语句是:
SELECT ... FROM tableA ??? JOIN tableB ON tableA.column1 = tableB.column2;我们把tableA看作左表,把tableB看成右表,那么INNER JOIN是选出两张表都存在的记录:

LEFT OUTER JOIN是选出左表存在的记录:
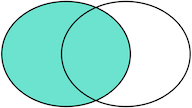
RIGHT OUTER JOIN是选出右表存在的记录:

FULL OUTER JOIN则是选出左右表都存在的记录:
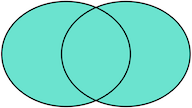
子查询
视图: 作为查询语句,动态生成虚拟的表
通过查询语句生成视图。
CREATE VIEW top10 AS select * from player order by level desc limit 10也可以查询普通表一样操作视图。
select * from top10也可以修改视图。
ALTER VIEW top10 AS select * from player order by level desc limit 10最后是删除视图。
DROP VIEW top10其他关键字
UNION: 链接查询结果
SELECT column_name(s) FROM table1 UNION SELECT column_name(s) FROM table2;UNION:⽤于合并两个或多个SELECT⼦句的结果(并集),默认去重复,如果允 许重复值,请使⽤UNION ALL。
SELECT DISTINCT name FROM students
UNION
SELECT DISTINCT name FROM students 上面的UNION会自动合并重复数据,如果需要保留可以使用 UNION ALL 。
SELECT DISTINCT name FROM students
UNION ALL
SELECT DISTINCT name FROM students INNERSESECT: 查找交集
SELECT column_name(s) FROM table1
INTERSECT
SELECT column_name(s) FROM table2;INTERSECT:⽤于合并两个或多个SELECT⼦句的结果(交集)
SELECT * FROM player WHERE level BETWEEN 1 AND 5 INTERSECT
SELECT * FROM player WHERE gold BETWEEN 1 AND 5;EXCEPT : 查找差集
SELECT column_name(s) FROM table1
EXCEPT
SELECT column_name(s) FROM table2;EXCEPT:⽤于合并两个或多个SELECT⼦句的结果(差集)。
SELECT * FROM player WHERE level BETWEEN 1 AND 5
EXCEPT
SELECT * FROM player WHERE gold BETWEEN 1 AND 5;DISTINCT:去除重复数据
SELECT DISTINCT name FROM students INDEX: 索引 ,提升遍历效率
【创建】
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name ON table_name (column_name(s));【查询】
SHOW INDEX FROM table_name【删除】
DROP INDEX index_name ON table_name;DML(Data Manipulation Language): 编辑数据
⽤来对数据库中的数据进⾏增删改操作。 相关关键字包括:INSERT、DELETE、UPDATE等。
INSERT
INSERT语句的基本语法是:
INSERT INTO <表名> (字段1, 字段2, ...) VALUES (值1, 值2, ...);例如,我们向students表插入一条新记录,先列举出需要插入的字段名称,然后在VALUES子句中依次写出对应字段的值:
INSERT INTO students (class_id, name, gender, score) VALUES (2, '大牛', 'M', 80);注意❗
注意到我们并没有列出
id字段,也没有列出id字段对应的值,这是因为id字段是一个自增主键,它的值可以由数据库自己推算出来。此外,如果一个字段有默认值,那么在INSERT语句中也可以不出现。
注意❗
要注意,字段顺序不必和数据库表的字段顺序一致,但值的顺序必须和字段顺序一致。也就是说,可以写
INSERT INTO students (score, gender, name, class_id) ...,但是对应的VALUES就得变成(80, 'M', '大牛', 2)。
还可以一次性添加多条记录,只需要在VALUES子句中指定多个记录值,每个记录是由(...)包含的一组值:
INSERT INTO students (class_id, name, gender, score) VALUES
(1, '大宝', 'M', 87),
(2, '二宝', 'M', 81);UPDATE
UPDATE语句的基本语法是:
UPDATE <表名> SET 字段1=值1, 字段2=值2, ... WHERE ...;例如,我们想更新students表id=1的记录的name和score这两个字段,先写出UPDATE students SET name='大牛', score=66,然后在WHERE子句中写出需要更新的行的筛选条件id=1:
UPDATE students SET name='大牛', score=66 WHERE id=1;注意到UPDATE语句的WHERE条件和SELECT语句的WHERE条件其实是一样的,因此完全可以一次更新多条记录:
UPDATE students SET name='小牛', score=77 WHERE id>=5 AND id<=7;在UPDATE语句中,更新字段时可以使用表达式。例如,把所有80分以下的同学的成绩加10分:
UPDATE students SET score=score+10 WHERE score<80;其中,SET score=score+10就是给当前行的score字段的值加上了10。
如果WHERE条件没有匹配到任何记录,UPDATE语句不会报错,也不会有任何记录被更新。例如:
UPDATE students SET score=100 WHERE id=999;最后,要特别小心的是,UPDATE语句可以没有WHERE条件,例如:
UPDATE students SET score=60;这时,整个表的所有记录都会被更新。所以,在执行UPDATE语句时要非常小心,最好先用SELECT语句来测试WHERE条件是否筛选出了期望的记录集,然后再用UPDATE更新。
DELETE
DELETE语句的基本语法是:
DELETE FROM <表名> WHERE ...;例如,我们想删除students表中id=1的记录,就需要这么写:
DELETE FROM students WHERE id=1;注意到DELETE语句的WHERE条件也是用来筛选需要删除的行,因此和UPDATE类似,DELETE语句也可以一次删除多条记录:
DELETE FROM students WHERE id>=5 AND id<=7;如果WHERE条件没有匹配到任何记录,DELETE语句不会报错,也不会有任何记录被删除。例如:
DELETE FROM students WHERE id=999;最后,要特别小心的是,和UPDATE类似,不带WHERE条件的DELETE语句会删除整个表的数据:
DELETE FROM students;这时,整个表的所有记录都会被删除。所以,在执行DELETE语句时也要非常小心,最好先用SELECT语句来测试WHERE条件是否筛选出了期望的记录集,然后再用DELETE删除。
DDL(Data Definition Language): 数据库管理
⽤来定义数据库对象,包括数据库、表、列等。 相关关键字包括:CREATE、DROP、ALTER等。
DDL -数据库
SHOW: 列出数据库
要列出所有数据库,使用命令:
mysql> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| shici |
| sys |
| test |
| school |其中,information_schema、mysql、performance_schema和sys是系统库,不要去改动它们。其他的是用户创建的数据库。
注意❗
注意:在MySQL命令行客户端输入SQL后,记得加一个
;表示SQL语句结束,再回车就可以执行该SQL语句。虽然有些SQL命令不需要;也能执行,但类似SELECT等语句不加;会让MySQL客户端换行后继续等待输入。如果在图形界面或程序开发中集成SQL则不需要加;。
CREATE:创建数据库
创建一个新数据库,使用命令:
mysql> CREATE DATABASE test;
Query OK, 1 row affected (0.01 sec)DROP: 删除数据库
要删除一个数据库,使用命令:
mysql> DROP DATABASE test;
Query OK, 0 rows affected (0.01 sec)注意:删除一个数据库将导致该数据库的所有表全部被删除。
USE: 切换数据库
对一个数据库进行操作时,要首先将其切换为当前数据库:
mysql> USE test;
Database changedDDL-数据表
SHOW: 列出数据表
列出当前数据库的所有表,使用命令:
mysql> SHOW TABLES;
+---------------------+
| Tables_in_test |
+---------------------+
| classes |
| statistics |
| students |
| students_of_class1 |
+-------DESC: 查看表结构
要查看一个表的结构,使用命令:
mysql> DESC students;
+----------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------+------+-----+---------+----------------+
| id | bigint(20) | NO | PRI | NULL | auto_increment |
| class_id | bigint(20) | NO | | NULL | |
| name | varchar(100) | NO | | NULL | |
| gender | varchar(1) | NO | | NULL | |
| score | int(11) | NO | | NULL | |
+----------+--------------+------+-----+---------+----------------+
5 rows in set (0.00 sec)CREATE: 创建数据表
使用以下命令查看创建表的SQL语句:
mysql> SHOW CREATE TABLE students;
+----------+-------------------------------------------------------+
| students | CREATE TABLE `students` ( |
| | `id` bigint(20) NOT NULL AUTO_INCREMENT, |
| | `class_id` bigint(20) NOT NULL, |
| | `name` varchar(100) NOT NULL, |
| | `gender` varchar(1) NOT NULL, |
| | `score` int(11) NOT NULL, |
| | PRIMARY KEY (`id`) |
| | ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 |
+----------+-------------------------------------------------------+
1 row in set (0.00 sec)DROP: 删除数据表
删除表使用DROP TABLE语句:
mysql> DROP TABLE students;
Query OK, 0 rows affected (0.01 sec)ALTER: 修改数据表
修改表就比较复杂。如果要给students表新增一列birth,使用:
ALTER TABLE students ADD COLUMN birth VARCHAR(10) NOT NULL;要修改birth列,例如把列名改为birthday,类型改为VARCHAR(20):
ALTER TABLE students CHANGE COLUMN birth birthday VARCHAR(20) NOT NULL;要删除列,使用:
ALTER TABLE students DROP COLUMN birthday;DDL- 其他
EXIT:退出数据库
使用EXIT命令退出MySQL:
mysql> EXIT
Bye注意❗
注意
EXIT仅仅断开了客户端和服务器的连接,MySQL服务器仍然继续运行。
mysqldump : 导入/导出数据
将数据库或数据表导出到文件中,通常用于数据备份。
mysqldump -u root -p game users > users.sql使用下面的命令可以从文件中导入数据。
mysql -u root -p game < game.sqlDCL(Data Control Language)
⽤来定义数据库的访问权限和安全级别。 相关关键字包括:GRANT、REVOKE等。
TCL(Transaction Control Language)
⽤来管理事务。 相关关键字包括:COMMIT、ROLLBACK等。