一、 渲染管线
1.1 有那几个坐标系(空间)?如何在空间之间进行转换?
我们在图形学中,一般会有五个坐标系,分别是:
- 物体坐标系(本地坐标系)Local Space 或 Model Space
- 世界坐标系 World Space
- 观察者坐标系(摄像机坐标系) View Space
- 裁剪空间 Clipping Space
- 屏幕空间 Screen Space
其中前四个矩阵之间,主要通过 model, view, projection 矩阵进行相关的变换, 裁剪空间到屏幕空间通过 **视口变换__进行;前三个是三维空间,后面两个是二维空间。
其转换过程如图1.1所示:
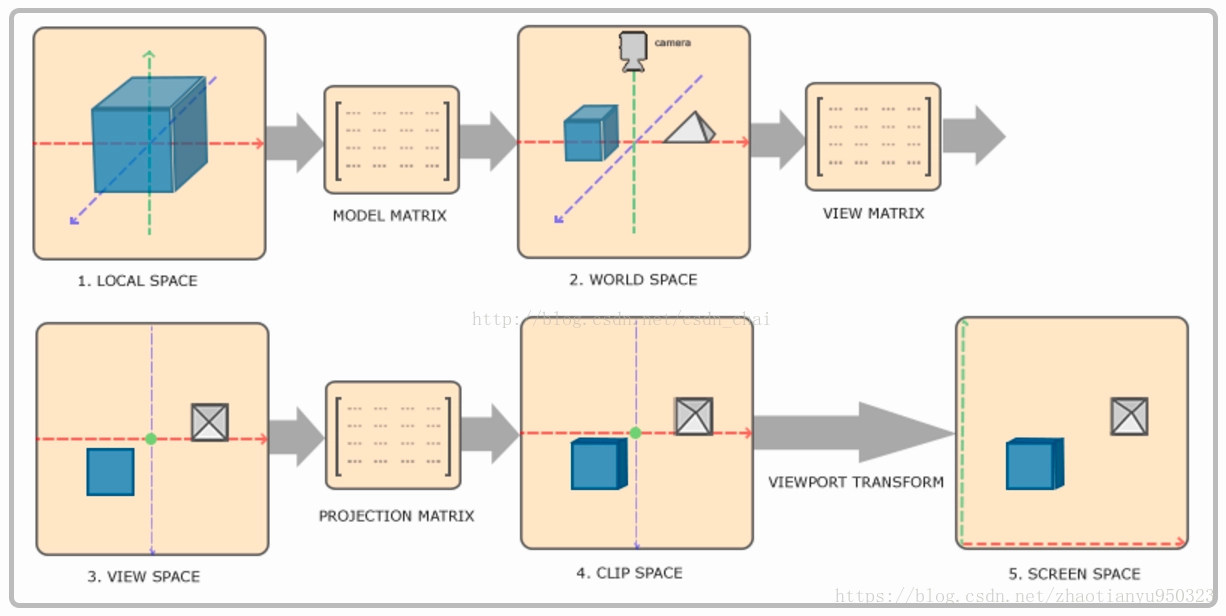
图1.1 坐标系(空间)的转换
所有的变换都发生在顶点着色器,经过顶点着色器,所有的顶点都变成了屏幕上的二维坐标,下一步是进行图元装配之后进入几何着色器。
1.2 三个重要的空间变换矩阵?作用是什么?
需要注意这三个矩阵在顶点着色器当中的作用:
- Model matrix 模型矩阵。进行物体坐标系到世界坐标系的转换。控制了物体的平移、旋转、缩放。在 3D 建模软件中为模型坐标,导入游戏后使用 model martrix 进行大小、位置、角度的相关设置。
- View matrix 观察矩阵。将世界坐标系变换到观察者坐标系,通过一些平移、旋转的组合来移动整个场景(而不是去移动摄像机,摄像机是一个虚拟的概念,事实上代码中并没有摄像机 camera 而是用 view martix 来表示摄像机,然后把 view matrix 附加到每一个物体,来模拟相关的摄像机操作),用来模拟一个摄像机。
- projection matrix 投影矩阵。将观察者坐标系转换到裁剪坐标系。将 3D 坐标投影到 2D 屏幕上,裁剪空间外的顶点会被裁掉,投影矩阵指定了坐标的范围。
1.3 视口变换是什么?
视口变换发生在投影到 2D 屏幕后,将投影之后归一化的点映射到屏幕上指定的一块区域。在 OpenGL 中,是利用 glViewPort 函数来进行指定的。
1.4 渲染管线的流程?
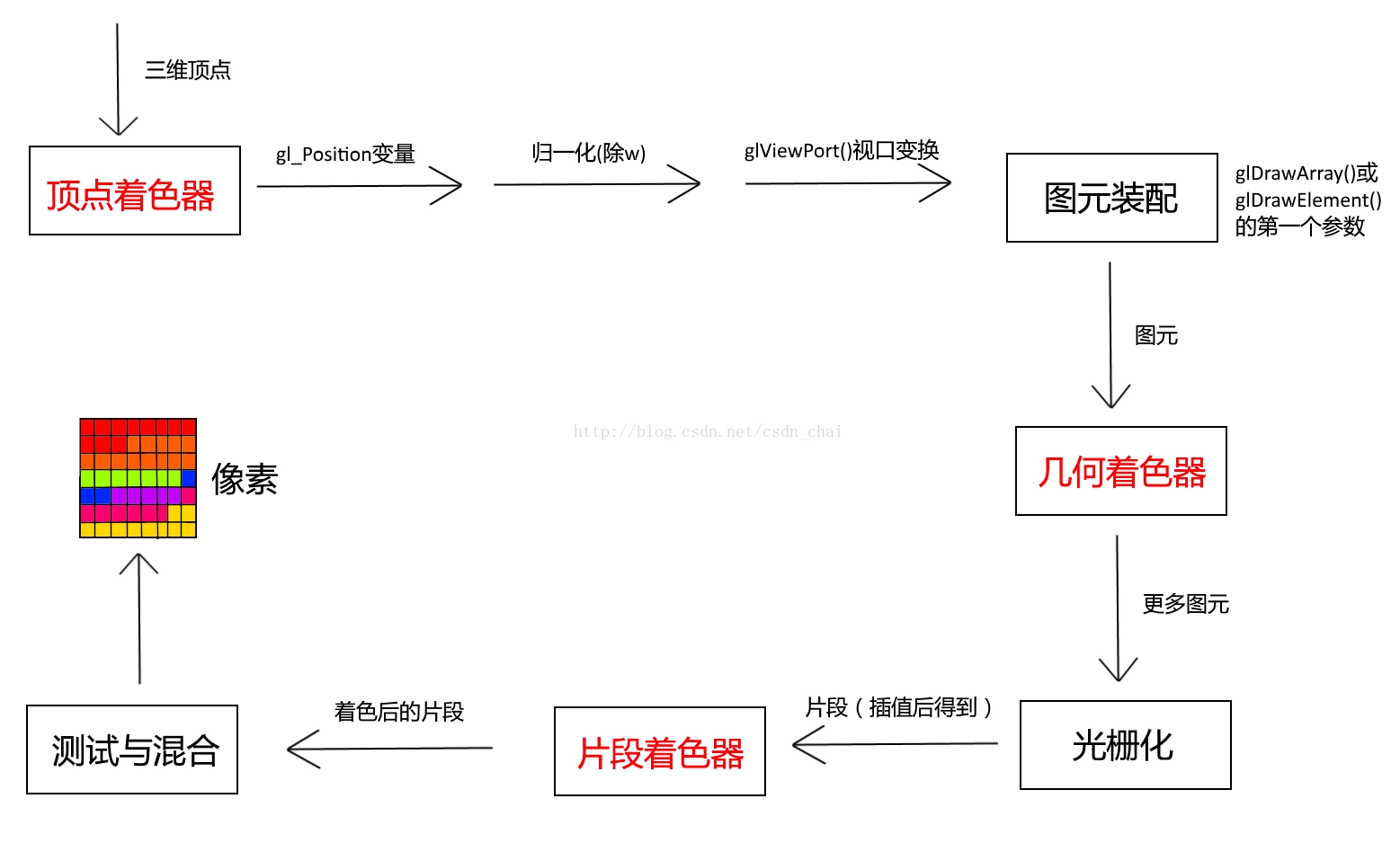
图1.2 渲染管线流程
这里有一张更加形象的图:
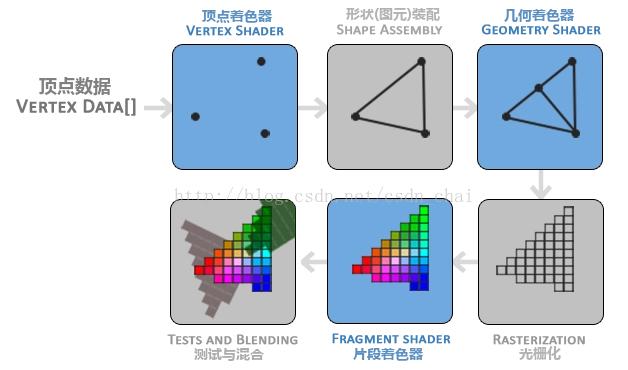
图1.3 渲染管线流程1
其中, gl_Position在从顶点着色器输出了之后,会用OpenGL自己的函数进行归一化和视口变换,其具体过程如下:
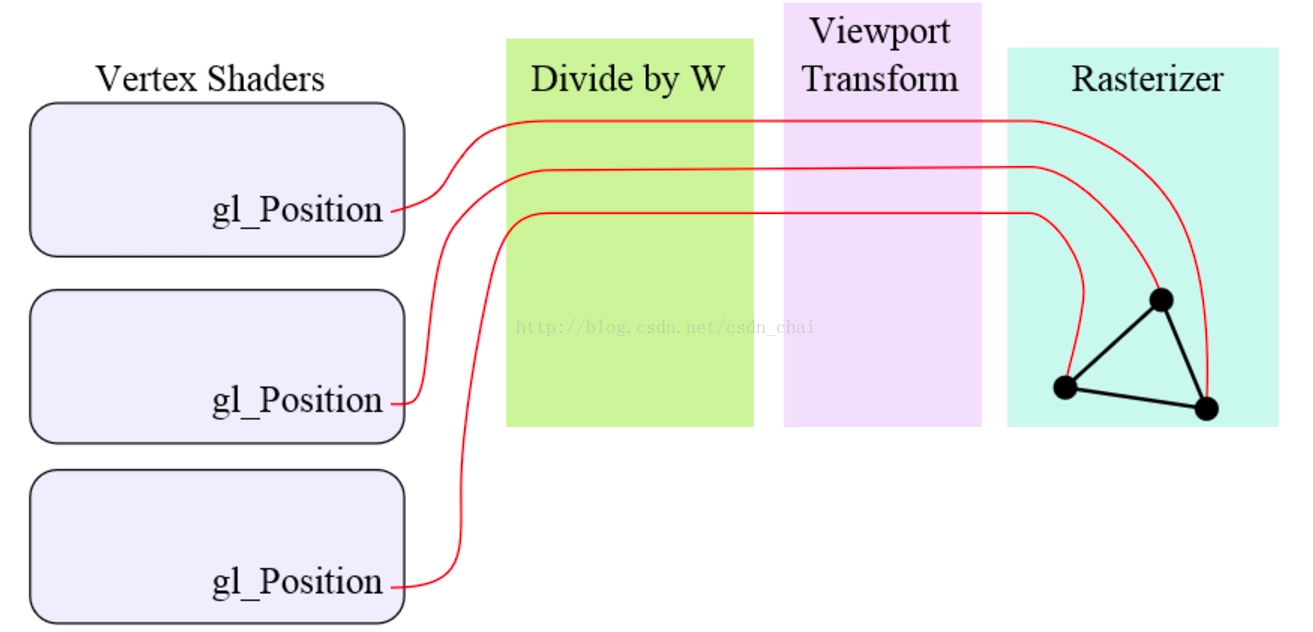
图1.4 归一化与视口变换过程
而片段处理程序的input是顶点处理程序的output经过了插值之后得到的值
1.5 三种着色器有什么用?各完成了什么过程?
- 顶点着色器:计算顶点的位置,并将顶点投影在二维屏幕上。
- 几何着色器:将形状(图元)划分为更多的形状(图元),影响后面的插值结果,例如可以将一个复杂的图形,转换为一个大规模旋转三角面片的组合图形,然后进行一个几何着色器的分片过程。
- 片段着色器:根据顶点着色器和几何着色器输出的插值,计算每一个片元的颜色。之后进行测试和混合后生成最终的像素。
1.6 什么是光栅化?
光栅(栅格化或者像素化)化负责的是整个渲染过程中的几何成像的环节,把几何图元(点,线,面)投影到成像平面并确定哪些像素或采样点被图元覆盖。举例来说:
- 输入,一个三角形的三个顶点,( x 0 , y 0 , z 0 , w 0 ) , ( x 1 , y 1 , z 1 , w 1 ) , ( x 2 , y 2 , z 2 , w 2 ) (x0, y0, z0, w0), (x1, y1, z1, w1), (x2, y2, z2, w2)(x0,y0,z0,w0),(x1,y1,z1,w1),(x2,y2,z2,w2)。
- 输出,这个三角形会覆盖屏幕上哪些像素,可以认为是_Point2d[]_

图1.5 圆形栅格化
1.7 OpenGL中有哪几种缓冲?都有什么用?
- 帧缓冲 Frame Buffer, 用于创建零时的渲染上下文,帧缓冲是一些二维数组和 OpenGL 所使用的存储区的结合:颜色缓存、深度缓存、模板缓存和累计缓存。默认情况下,OpenGL 将帧缓冲区作为渲染的最终目的地。此帧缓冲区完全有window系统生成和管理。这个默认的帧缓存被称作“window系统生成”(window-system-provided)的帧缓冲区。
- 颜色缓冲 Color Buffer, 包含每个像素的颜色信息。颜色信息可以是颜色的索引(在颜色索引方式下),也可以是颜色的红、绿、蓝3个分量(在_RGBA_方式下),还可以存放表示物体透明程度的_Alpha_值。
- 深度缓冲 Depth Buffer, 包含每个像素的深度值。深度值与z轴坐标有关,描述物体上某点距离观察点的远近,也可以称之为Z缓存(Z Buffer)。
- 模板缓冲 Stencil Buffer, 包含物体的模板值。模板值具有屏蔽的作用,用于控制绘制的区域,使屏幕上某些区域可画,某些区域不可画。
- 累计缓存 Accumulation Buffer 包含颜色信息,其可以合成一系列的挥之效果,实现某些特殊效果。
- 顶点缓冲 Vertex Buffer , 用于缓存顶点数据
- 元素缓冲 Element Buffer, 用于缓存顶点序号数据
1.8 Alpha 混合的几种方式?
通用公式:

其中Color是混合结果, Src是源颜色向量也就是纹理本来的颜色,Dst是目标颜色向量也就是储存在颜色缓冲中当前位置的颜色向量,SrcFactor 和DstFactor 分别是源因子和目标因子。先进入颜色缓冲区的是目标颜色, 比如在红色方块上绘制绿色方块,则红色是Dst, 绿色是Src。 不同的factor导致了不同的混合方式:
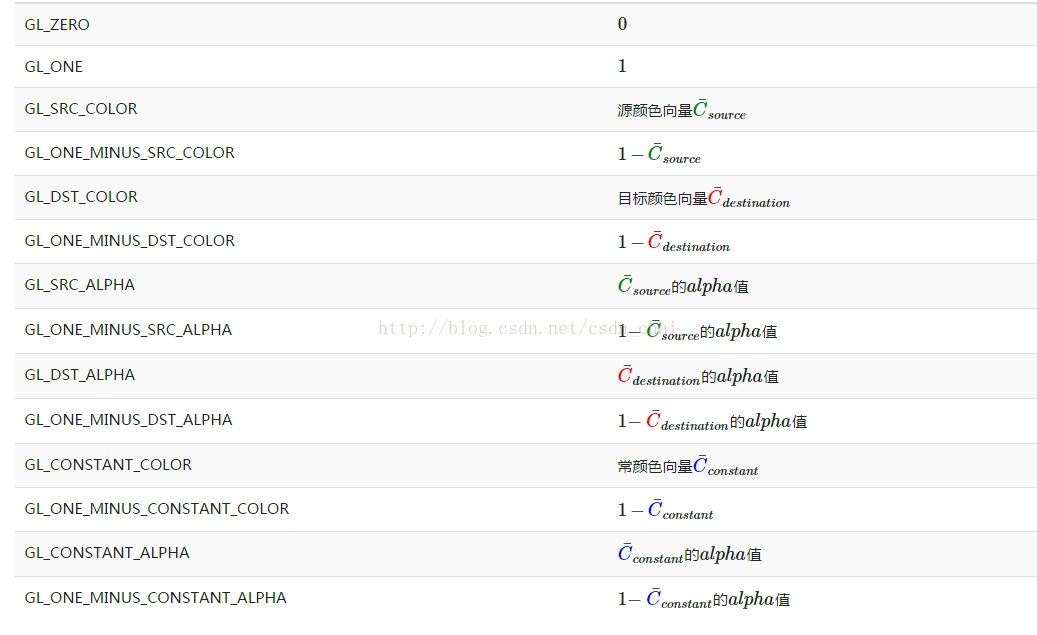
图1.6 Alpha颜色通道
注意,颜色常数向量可以用 glBlendColor 函数分开来设置。 OpenGL 使用 void glBlendFunc(GLenum sfactor, GLenum dfactor) 设置相关的混合方式,接受两个参数,来设置源(source) 和目标 (destination) 因子。OpenGL 为我们定义了很多选项,我们把最常用的列在下面了。注意,颜色常数向量_[Math Processing Error]C_constant_ 可以用 glBlendColor 函数来分开设置。在使用 alpha 混合之前需要开启 glEnable(GL_BLEND);
最常用的混合方式就是: glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA)
1.9 颜色向量的计算
颜色向量(归一化的)有两种计算:

1.10 GLSL着色器程序的创建
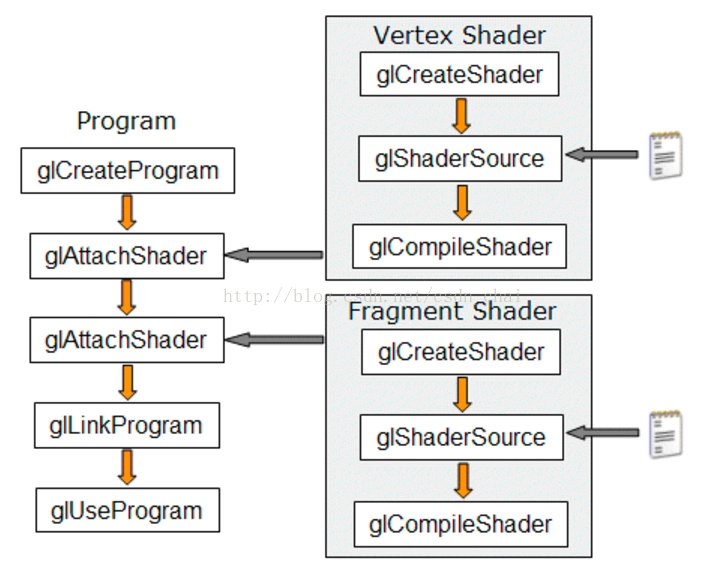
图1.7 GLSL着色器创建过程
1.11 _GLSL_数据传递有几种方式?
- uniform 变量, uniform 变量是外部_application_ 程序传递给(vertex 和 fragment)shader 的变量。因此它是_application_通过函数 glUniform() 赋值的, 在(vertex_和_fragment)_shader_程序内部, uniform 变量就像是 C 语言的常量(const) , 它不能被 shader 程序修改。
- attribute 变量, attribute_变量是智能在_vertex shader_中使用的变量。(它不能在_fragment shader_中声明_attribute 变量,也不能被_fragment shader_中使用)。 一般用 attribute 变量来表示一些顶点的数据,如:顶点坐标,法线,纹理坐标,顶点颜色等。在 application 中, 一般用函数 glBindAttribLocation() 来绑定每个 attribute 变量的位置,然后用函数 glVertexAttribPointer() 为每个 attribute 变量赋值。
- varying(in/out) 变量, _varying * 变量是 vertex* 和 fragment shader 之间做数据传递用的。 一般 vertex shader 修改 varying 变量的值, 然后_fragment shader 使用该 varying 变量的值。 因此 varying * 变量在 vertex* 和 fragment shader 二者之间的声明必须是一致的。application 不能使用此变量。
1.12 为什么要用齐次坐标系
- 方便进行平移变换
- 能够简化透视投影的计算
1.13 冯氏光照模型由哪三个部分构成?
光照要处理的就是光颜色向量和物体颜色向量的点积。三种光照可以组合使用(*ambient + diffuse + specular * * objectColor)。
- 环境光 amibient. 控制因素是_ambient strength_ 环境光强度,和_lightcolor_ 数乘得到_amibient* 环境光*。 然后再用_ambient 和物体颜色_objectColor_点乘。 ambient strength 由程序员指定。
- 漫反射_diffuse_, 控制因素是_diff散射因子_, 也是和_lightcolor_ 数乘得到_diffuse_ 漫反射光, 然后再用_diffuse_ 和 _objectColor_点乘。 diff 散射因子由法线与光线的夹角(点积) 得到, 漫反射使物体上与光线排布越近的片段越能从光源处获得更多的亮度 。 为了更好的理解漫反射光照,我们来看一个模型:

图1.8 漫反射模型1
1. $\theta$越大, 光对片段颜色的影响越小, 反过来光线越靠近法线, 对物体颜色的影响越大。
2. $float diff = max(dot(norm, lightDir),0.0)$; 两个向量之间的角度越大,散射因子就会越小。
- 镜面反射 specular, 控制因素 spec 反射强度。 和环境光照一样,镜面光照(Specular Lighting) 同样依据光的方向向量和物体的法向量, 但是这次他会依据观察方向,例如玩家是从什么方向看着这个片段的。镜面反射光照根据光的反射特性。如果我们想象物体表面像一面镜子一样,那么,无论我们从哪里去看那个表面所反射的光, 镜面光照都会达到最大化。

图1.9 漫反射观察者视角
1. 通过反射法向量周围光的方向计算反射向量。 然后我们计算反射向量和视线方向的角度,如果之间的角度越小,那么镜面广德作用就会越大。 它的作用效果就是,当我们去看光被物体所反射的那个方向的时候,我们就会看到一个高光。
1.14 旋转的三种方法
- 旋转矩阵 4x4
- 欧拉角 yaw pitch roll
- 四元数
1.15 四元数 Quaternion 的概念和作用
四元数本质上是一种高阶复数(听不懂了吧。。。),是一个四维空间,相对于复数的二维空间。我们高中的时候应该都学过复数,一个复数由实部和虚部组成,即x=a+bi,i ii是虚数单位,如果你还记得的话应该知道i2=−1。而四元数其实和我们学到的这种是类似的,不同的是,它的虚部包含了三个虚数单位,i、j、k,即一个四元数可以表示为x=a+bi+cj+dk。那么,它和旋转为什么会有关系呢?
在 Unity 里,tranform 组件有一个变量名为 rotation,它的类型就是四元数。很多初学者会直接取 rotation 的x 、 y 、 z x、y、zx、y、z,认为它们分别对应了_Transform_面板里R的各个分量。当然很快我们就会发现这是完全不对的。实际上,四元数的x 、 y 、 z x、y、zx、y、z和R RR的那三个值从直观上来讲没什么关系,当然会存在一个表达式可以转换。
1.16 四元数、欧拉数、旋转矩阵的优点和缺点
- 矩阵旋转
- 优点:
- 旋转轴可以使任意向量;
- 缺点:
- 旋转其实只需要知道一个向量 + 一个角度, 一共4个值的信息,但矩阵却使用了16个元素;
- 而且在做乘法操作时也会增加计算量,造成了空间和时间上的一些浪费;
- 优点:
- 欧拉旋转
- 优点:
- 很容易理解,形象直观;
- 表示更方便,只需要3个值(分别对应x , y , z x, y, zx,y,z轴的旋转角度);但依照其他博主的理解,她还是转换到了3个 3*3的矩阵变换,效率不如四元数;
- 缺点:
- 优点:
- 四元数旋转
- 优点:
- 可以避免万向节锁现象;
- 只需要一个4维的四元数就可以执行绕任意过原点的向量的旋转,方便快捷,在某些实现下比旋转矩阵效率更高;
- 可以提供平滑插值;
- 缺点:
- 比欧拉选择稍微复杂了一点点,因为多了一个维度;
- 理解更困难,不直观;
- 优点:
1.17 多级渐进纹理 mipmap ?有什么优缺点?
为了加快渲染速度和减少图像锯齿, 贴图被处理成由一系列被预先计算和优化过的图片组成的文件,这样的贴图被称为 MIP map 或者 mipmap
多级渐进纹理由一组分辨率逐渐降低的纹理序列组成,每一级纹理宽度和高度都是上一级纹理宽度和高度的一半。宽和高不一定相等,也就是说,这些纹理不一定都是正方形。
优点:提高渲染速度,减少图像锯齿
缺点:会增加额外的内存消耗。
1.18 片段和像素的区别?
- 片段是渲染一个像素需要的全部信息,所有片段经过测试与混合后渲染成像素。
- 片段是三维定点光栅化后的数据集合, 还没经过深度测试,而像素是片段经过深度测试、模板测试、alpha 混合之后的结果。
- 片段的个数远远多于像素, 因为有的片段会在测试和混合阶段被丢弃, 无法被渲染成像素。
1.19 深度缓存算法(zbuffer算法)
- 需要一个空间保存每个像素的深度,绘制前初始化所有深度为无限远,绘制时当前片段如果比zbuffer中的值大(说明更远),则跳过此片段,保留原来的渲染结果;否则,绘制此片段,并更新zbuffer
- 可以处理对透明物体的消除
- 算法可以并行
- 与画家算法不同,不需要对物体排序
二、数学基础
2.1 平面上N个点,每两个点都确定一条直线,求出斜率最大的那条直线所通过的两个点。
平面上N个点,每两个点都确定一条直线,
求出斜率最大的那条直线所通过的两个点(斜率不存在的情况不考虑)。时间效率越高越好。
平面上N个点,每两个点都确定一条直线,求出斜率最大的那条直线所通过的两个点(斜率不存在的情况不考虑)。时间效率越高越好。
关于这道题,网上已经给出了解答要点:
3个点A,B,C,把它们的按x坐标排序。假设排序后的顺序是ABC,那么有两种情况:
1. ABC共线,则$k(AB)=k(BC)=k(AC)$
2. ABC不共线,则ABC将形成一个三角形,那么$k(AC)<max(k(AB), k(BC))$
其中k是斜率。
程序的基本步骤是:
1. 把N个点按x坐标排序
2. 遍历,求相邻的两个点的斜率,找最大值
时间复杂度 Nlong(N)
先把这些点按x坐标从小到大排序,斜率最大的两点必然是挨一起的两个点,所以排序O(n∗lgn),遍历一次O ( n ) O(n)O(n)就够了